Why traditional code search is challenging
Anyone who works with code knows the frustration of searching across repositories. Whether you're a developer debugging an issue, a DevOps engineer examining configurations, a security analyst searching for vulnerabilities, a technical writer updating documentation, or a manager reviewing implementation, you know exactly what you need, but traditional search tools often fail you.
These conventional tools return dozens of false positives, lack the context needed to understand results, and slow to a crawl as codebases grow. The result? Valuable time spent hunting for needles in haystacks instead of building, securing, or improving your software.
GitLab's code search functionality has historically been backed by Elasticsearch or OpenSearch. While these are excellent for searching issues, merge requests, comments, and other data containing natural language, they weren't specifically designed for code. After evaluating numerous options, we developed a better solution.
Introducing Exact Code Search: Three game-changing capabilities
Enter GitLab's Exact Code Search, currently in beta testing and powered by Zoekt (pronounced "zookt", Dutch for "search"). Zoekt is an open-source code search engine originally created by Google and now maintained by Sourcegraph, specifically designed for fast, accurate code search at scale. We've enhanced it with GitLab-specific integrations, enterprise-scale improvements, and seamless permission system integration.
This feature revolutionizes how you find and understand code with three key capabilities:
1. Exact Match mode: Zero false positives
When toggled to Exact Match mode, the search engine returns only results that match your query exactly as entered, eliminating false positives. This precision is invaluable when:
- Searching for specific error messages
- Looking for particular function signatures
- Finding instances of specific variable names
2. Regular Expression mode: Powerful pattern matching
For complex search needs, Regular Expression mode allows you to craft sophisticated search patterns:
- Find functions following specific naming patterns
- Locate variables matching certain constraints
- Identify potential security vulnerabilities using pattern matching
3. Multiple-line matches: See code in context
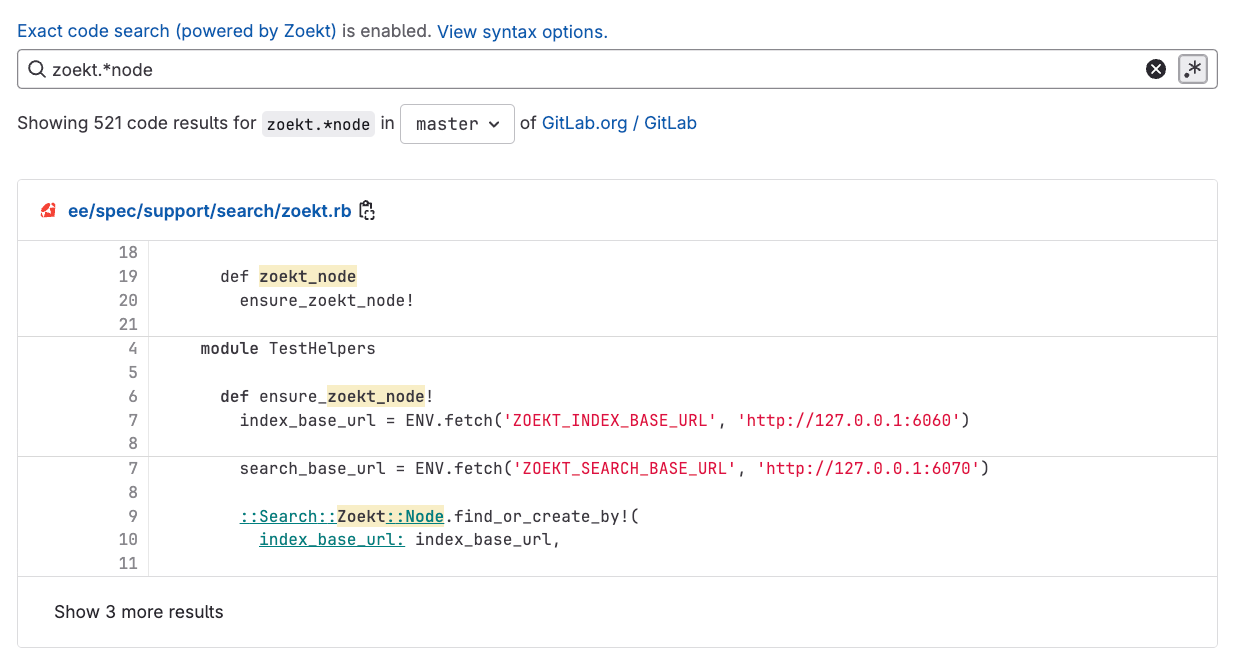
Instead of seeing just a single line with your matching term, you get the surrounding context that's crucial for understanding the code. This eliminates the need to click through to files for basic comprehension, significantly accelerating your workflow.
From features to workflows: Real-world use cases and impact
Let's see how these capabilities translate to real productivity gains in everyday development scenarios:
Debugging: From error message to root cause in seconds
Before Exact Code Search: Copy an error message, search, wade through dozens of partial matches in comments and documentation, click through multiple files, and eventually find the actual code.
With Exact Code Search:
- Copy the exact error message
- Paste it into Exact Code Search with Exact Match mode
- Instantly find the precise location where the error is thrown, with surrounding context
Impact: Reduce debugging time from minutes to seconds, eliminating the frustration of false positives.
Code exploration: Master unfamiliar codebases quickly
Before Exact Code Search: Browse through directories, make educated guesses about file locations, open dozens of files, and slowly build a mental map of the codebase.
With Exact Code Search:
- Search for key methods or classes with Exact Match mode
- Review multiple line matches to understand implementation details
- Use Regular Expression mode to find similar patterns across the codebase
Impact: Build a mental map of code structure in minutes rather than hours, dramatically accelerating onboarding and cross-team collaboration.
Refactoring with confidence
Before Exact Code Search: Attempt to find all instances of a method, miss some occurrences, and introduce bugs through incomplete refactoring.
With Exact Code Search:
- Use Exact Match mode to find all occurrences of methods or variables
- Review context to understand usage patterns
- Plan your refactoring with complete information about impact
Impact: Eliminate the "missed instance" bugs that often plague refactoring efforts, improving code quality and reducing rework.
Security auditing: Finding vulnerable patterns
Security teams can:
- Create regex patterns matching known vulnerable code
- Search across all repositories in a namespace
- Quickly identify potential security issues with context that helps assess risk
Impact: Transform security audits from manual, error-prone processes to systematic, comprehensive reviews.
Cross-repository insights
Search across your entire namespace or instance to:
- Identify similar implementations across different projects
- Discover opportunities for shared libraries or standardization
Impact: Break down silos between projects and identify opportunities for code reuse and standardization.
The technical foundation: How Zoekt delivers speed and precision
Before diving into our scale achievements, let's explore what makes Zoekt fundamentally different from traditional search engines — and why it can find exact matches so incredibly fast.
Positional trigrams: The secret to lightning-fast exact matches
Zoekt's speed comes from its use of positional trigrams — a technique that indexes every sequence of three characters along with their exact positions in files. This approach solves one of the biggest pain points developers have had with Elasticsearch-based code search: false positives.
Here's how it works:
Traditional full-text search engines like Elasticsearch tokenize code into words and lose positional information. When you search for getUserId(), they might return results containing user, get, and Id scattered throughout a file — leading to those frustrating false positives for GitLab users.
Zoekt's positional trigrams maintain exact character sequences and their positions. When you search for getUserId(), Zoekt looks for the exact trigrams like get, etU, tUs, Use, ser, erI, rId, Id(", "d(), all in the correct sequence and position. This ensures that only exact matches are returned.
The result? Search queries that previously returned hundreds of irrelevant results now return only the precise matches you're looking for. This was one of our most requested features for good reason - developers were losing significant time sifting through false positives.
Regular expression performance at scale
Zoekt excels at exact matches and is optimized for regular expression searches. The engine uses sophisticated algorithms to convert regex patterns into efficient trigram queries when possible, maintaining speed even for complex patterns across terabytes of code.
Built for enterprise scale
Exact Code Search is powerful and built to handle massive scale with impressive performance. This is not just a new UI feature — it's powered by a completely reimagined backend architecture.
Handling terabytes of code with ease
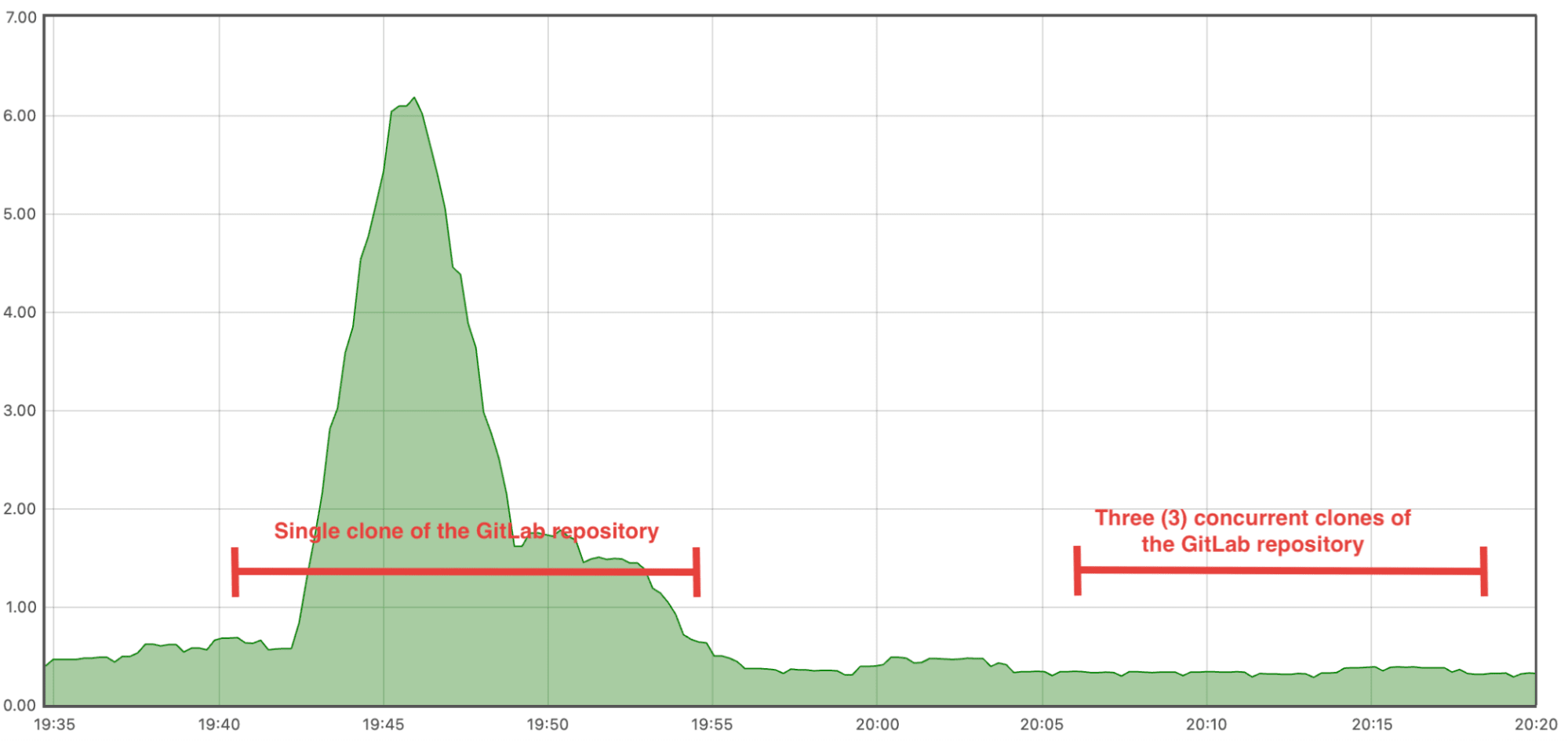
On GitLab.com alone, our Exact Code Search infrastructure indexes and searches over 48 TB of code data while maintaining lightning-fast response times. This scale represents millions of repositories across thousands of namespaces, all searchable within milliseconds. To put this in perspective: This scale represents more code than the entire Linux kernel, Android, and Chromium projects combined. Yet Exact Code Search can find a specific line across this massive codebase in milliseconds.
Self-registering node architecture
Our innovative implementation features:
- Automatic node registration: Zoekt nodes register themselves with GitLab
- Dynamic shard assignment: The system automatically assigns namespaces to nodes
- Health monitoring: Nodes that don't check in are automatically marked offline
This self-configuring architecture dramatically simplifies scaling. When more capacity is needed, administrators can simply add more nodes without complex reconfiguration.
Distributed system with intelligent load balancing
Behind the scenes, Exact Code Search operates as a distributed system with these key components:
- Specialized search nodes: Purpose-built servers that handle indexing and searching
- Smart sharding: Code is distributed across nodes based on namespaces
- Automatic load balancing: The system intelligently distributes work based on capacity
- High availability: Multiple replicas ensure continuous operation even if nodes fail
Note: High availability is built into the architecture but not yet fully enabled. See Issue 514736 for updates.
Seamless security integration
Exact Code Search automatically integrates with GitLab's permission system:
- Search results are filtered based on the user's access rights
- Only code from projects the user has access to is displayed
- Security is built into the core architecture, not added as an afterthought
Optimized performance
- Efficient indexing: Large repositories are indexed in tens of seconds
- Fast query execution: Most searches return results with sub-second response times
- Streaming results: The new gRPC-based federated search streams results as they're found
- Early termination: Once enough results are collected, the system pauses searching
From library to distributed system: Engineering challenges we solved
While Zoekt provided the core search technology, it was originally designed as a minimal library for managing .zoekt index files - not a distributed database or enterprise-scale service. Here are the key engineering challenges we overcame to make it work at GitLab's scale"
Challenge 1: Building a orchestration layer
The problem: Zoekt was designed to work with local index files, not distributed across multiple nodes serving many concurrent users.
Our solution: We built a comprehensive orchestration layer that:
- Creates and manages database models to track nodes, indices, repositories, and tasks
- Implements a self-registering node architecture (inspired by GitLab Runner)
- Handles automatic shard assignment and load balancing across nodes
- Provides bidirectional API communication between GitLab Rails and Zoekt nodes
Challenge 2: Scaling storage and indexing
The problem: How do you efficiently manage terabytes of index data across multiple nodes while ensuring fast updates?
Our solution: We implemented:
- Intelligent sharding: Namespaces are distributed across nodes based on capacity and load
- Independent replication: Each node independently indexes from Gitaly (our Git storage service), eliminating complex synchronization
- Watermark management: Sophisticated storage allocation that prevents nodes from running out of space
- Unified binary architecture: A single
gitlab-zoektbinary that can operate in both indexer and webserver modes
Challenge 3: Permission Integration
The problem: Zoekt had no concept of GitLab's complex permission system - users should only see results from projects they can access.
Our solution: We built native permission filtering directly into the search flow:
- Search requests include user permission context
- Results are filtered to include only those the user can access in case permissions change before indexing completes
Challenge 4: Operational simplicity
The problem: Managing a distributed search system shouldn't require a dedicated team.
Our solution:
- Auto-scaling: Adding capacity is as simple as deploying more nodes - they automatically register and start handling work
- Self-healing: Nodes that don't check in are automatically marked offline and their work redistributed
- Zero-configuration sharding: The system automatically determines optimal shard assignments
Gradual rollout: Minimizing risk at scale
Rolling out a completely new search backend to millions of users required careful planning. Here's how we minimized customer impact while ensuring reliability:
Phase 1: Controlled testing (gitlab-org group)
We started by enabling Exact Code Search only for the gitlab-org group - our own internal repositories. This allowed us to:
- Test the system with real production workloads
- Identify and fix performance bottlenecks
- Streamline the deployment process
- Learn from real users' workflows and feedback
Phase 2: Performance validation and optimization
Before expanding, we focused on ensuring the system could handle GitLab.com's scale:
- Implemented comprehensive monitoring and alerting
- Validated storage management with real production data growth
Phase 3: Incremental customer expansion
We gradually expanded to customers interested in testing Exact Code Search:
- Gathered feedback on performance and user experience
- Refined the search UI based on real user workflows
- Optimized indexing performance (large repositories like
gitlab-org/gitlabnow index in ~10 seconds) - Refined the architecture based on operational learnings
- Massively increased indexing throughput and improved state transition livecycle
Phase 4: Broad rollout
Today, over 99% of Premium and Ultimate licensed groups on GitLab.com have access to Exact Code Search. Users can:
- Toggle between regex and exact search modes
- Experience the benefits without any configuration changes
- Fall back to the previous search if needed (though few choose to)
Rolling this out gradually meant users didn't experience service disruptions, performance degradation, or feature gaps during the transition. We've already received positive feedback from users as they notice their results becoming more relevant and faster.
For technical deep dive: Interested in the detailed architecture and implementation? Check out our comprehensive design document for in-depth technical details about how we built this distributed search system.
Getting started with Exact Code Search
Getting started with Exact Code Search is simple because it's already enabled by default for Premium and Ultimate groups on GitLab.com (over 99% of eligible groups currently have access).
Quickstart guide
- Navigate to the Advanced Search in your GitLab project or group
- Enter your search term in the code tab
- Toggle between Exact Match and Regular Expression modes
- Use filters to refine your search
Basic search syntax
Whether using Exact Match or Regular Expression mode, you can refine your search with modifiers:
| Query Example | What It Does |
|---|---|
file:js |
Searches only in files containing "js" in their name |
foo -bar |
Finds "foo" but excludes results with "bar" |
lang:ruby |
Searches only in Ruby files |
sym:process |
Finds "process" in symbols (methods, classes, variables) |
Pro Tip: For the most efficient searches, start specific and then broaden if needed. Using
file:andlang:filters dramatically increases relevance.
Advanced search techniques
Stack multiple filters for precision:
is_expected file:rb -file:spec
This finds "is_expected" in Ruby files that don't have "spec" in their name.
Use regular expressions for powerful patterns:
token.*=.*[\"']
Watch this search performed against the GitLab Zoekt repository.
The search helps find hardcoded passwords, which, if not found, can be a security issue.
For more detailed syntax information, check the Exact Code Search documentation.
Availability and deployment
Current availability
Exact Code Search is currently in Beta for GitLab.com users with Premium and Ultimate licenses:
- Available for over 99% of licensed groups
- Search in the UI automatically uses Zoekt when available, Exact Code Search in Search API is behind a feature flag
Self-managed deployment options
For self-managed instances, we offer several deployment methods:
- Kubernetes/Helm: Our most well-supported method, using our
gitlab-zoektHelm chart - Other deployment options: We're working on streamlining deployment for Omnibus and other installation methods
System requirements depend on your codebase size, but the architecture is designed to scale horizontally and/or vertically as your needs grow.
What's coming next
While Exact Code Search is already powerful, we're continuously improving it:
- Scale optimizations to support instances with hundreds of thousands of repositories
- Improved self-managed deployment options, including streamlined Omnibus support
- Full high availability support with automatic failover and load balancing
Stay tuned for updates as we move from Beta to General Availability.
Transform how you work with code
GitLab's Exact Code Search represents a fundamental rethinking of code discovery. By delivering exact matches, powerful regex support, and contextual results, it solves the most frustrating aspects of code search:
- No more wasting time with irrelevant results
- No more missing important matches
- No more clicking through files just to understand basic context
- No more performance issues as codebases grow
The impact extends beyond individual productivity:
- Teams collaborate better with easy code referencing
- Knowledge sharing accelerates when patterns are discoverable
- Onboarding becomes faster with quick codebase comprehension
- Security improves with effective pattern auditing
- Technical debt reduction becomes more feasible
Exact Code Search isn't just a feature, it's a better way to understand and work with code. Stop searching and start finding.
We'd love to hear from you! Share your experiences, questions, or feedback about Exact Code Search in our feedback issue. Your input helps us prioritize improvements and new features.
]]>Ready to experience smarter code search? Learn more in our documentation or try it now by performing a search in your Premium or Ultimate licensed namespaces or projects. Not a GitLab user yet? Try a free, 60-day trial of GitLab Ultimate with Duo!